Recent advancements in diffusion-based models have demonstrated significant success in generating images from text. However, video editing models have not yet reached the same level of visual quality and user control. To address this, we introduce RAVE, a zero-shot video editing method that leverages pre-trained text-to-image diffusion models without additional training. RAVE takes an input video and a text prompt to produce high-quality videos while preserving the original motion and semantic structure. It employs a novel noise shuffling strategy, leveraging spatio-temporal interactions between frames, to produce temporally consistent videos faster than existing methods. It is also efficient in terms of memory requirements, allowing it to handle longer videos. RAVE is capable of a wide range of edits, from local attribute modifications to shape transformations. In order to demonstrate the versatility of RAVE, we create a comprehensive video evaluation dataset ranging from object-focused scenes to complex human activities like dancing and typing, and dynamic scenes featuring swimming fish and boats. Our qualitative and quantitative experiments highlight the effectiveness of RAVE in diverse video editing scenarios compared to existing methods.
|
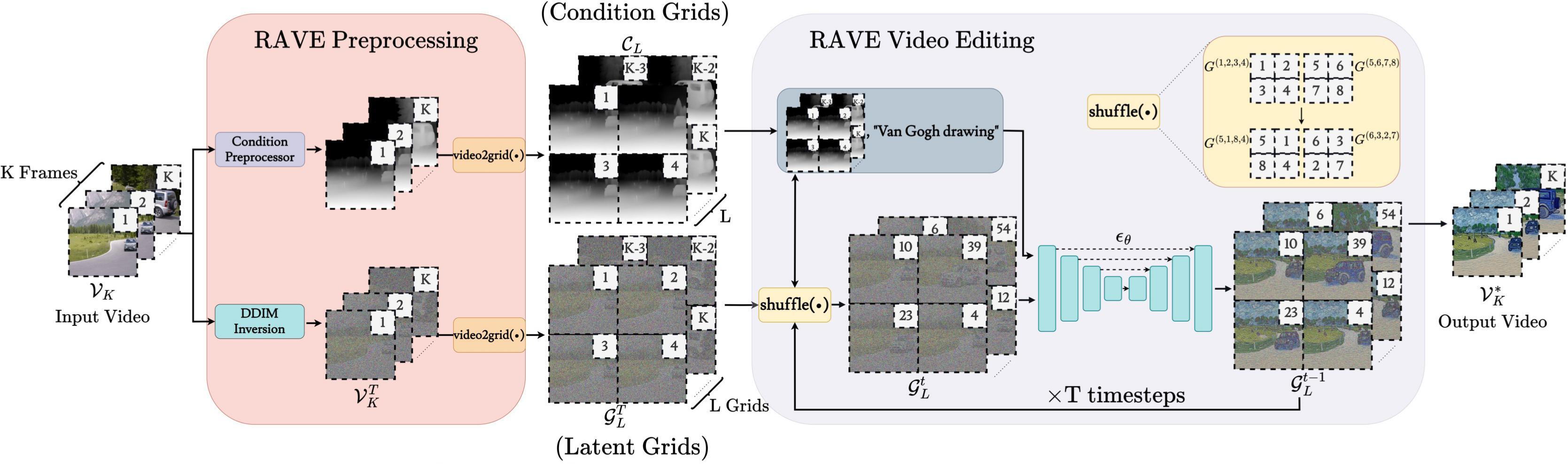
Our process begins by performing a DDIM inversion with the pre-trained T2I model and condition extraction with an off-the-shelf condition preprocessor applied to the input video ($V_K$). These conditions are subsequently input into ControlNet. In the RAVE video editing process, diffusion denoising is performed for T timesteps using condition grids ($C_L$), latent grids ($G_L^t$), and the target text prompt as input for ControlNet. Random shuffling is applied to the latent grids ($G_L^t$) and condition grids ($C_L$) at each denoising step. After T timesteps, the latent grids are rearranged, and the final output video ($V_K^*$) is obtained. |
For more results please see the supplementary material: Supplementary
Input Video
"An ancient Egyptian pharaoh is typing"
"A medieval knight"
"A zombie is typing"
Input Video
"A dinosaur"
"A black panther"
"A shiny silver robotic wolf, futuristic"
Input Video
"White cupcakes, moving on the table"
"Swarovski blue crystal train on the railway track"
"A train moving on the railway track in autumn, maple leaves"
Input Video
"Swarovski blue crystal stones falling down sequentially"
"Crochet boxes, falling down sequentially"
Input Video
"Swarovski blue crystal swan"
"Crochet swan"
Input Video
"A firefighter is stretching"
"Watercolor style"
"A zombie is stretching"
Input Video
"A jeep moving in the grassy field"
"A spaceship is moving throught the milky way"
"Van gogh style"
Input Video
"A tractor"
"Switzerland SBB CFF FFS train"
"A firetruck"
To view the original video, hover your mouse over the video.
Local Editing
Visual Style Editing
Background Editing
Shape/Attribute Editing
Extreme Shape Editing
"A man wearing a glitter jacket is typing"
"Watercolor style"
"A monkey is playing on the coast"
"A dinosaur"
"A tractor"
Exo-Motion
Ego-Motion
Ego-Exo Motion
Occlusions
Multiple Objects with Appearance/Disappearance
"Crochet swan"
"Anime style"
"Wooden trucks drive on a racetrack"
"A cheetah is moving"
"whales are swimming"
@inproceedings{kara2024rave,
title={RAVE: Randomized Noise Shuffling for Fast and Consistent Video Editing with Diffusion Models},
author={Ozgur Kara and Bariscan Kurtkaya and Hidir Yesiltepe and James M. Rehg and Pinar Yanardag},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}[1] Michal Geyer, Omer Bar-Tal, Shai Bagon, and Tali Dekel. Tokenflow: Consistent diffusion features for consistent video editing. arXiv preprint arXiv:2307.10373, 2023.
[2] Chenyang QI, Xiaodong Cun, Yong Zhang, Chenyang Lei, Xintao Wang, Ying Shan, and Qifeng Chen. Fatezero: Fusing attentions for zero-shot text-based video editing. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15932–15942, 2023.
[3] Shuai Yang, Yifan Zhou, Ziwei Liu, , and Chen Change Loy. Rerender a video: Zero-shot text-guided video-to-video translation. In ACM SIGGRAPH Asia Conference Proceedings, 2023.
[4] Levon Khachatryan, Andranik Movsisyan, Vahram Tadevosyan, Roberto Henschel, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Text2video-zero: Text-to-image diffusion models are zero-shot video generators. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15954–15964, 2023.
[5] Duygu Ceylan, Chun-Hao P Huang, and Niloy J Mitra. Pix2video: Video editing using image diffusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 23206–23217, 2023.
[6] Yuren Cong, Mengmeng Xu, Christian Simon, Shoufa Chen, Jiawei Ren, Yanping Xie, Juan-Manuel Perez-Rua, Bodo Rosenhahn, Tao Xiang, and Sen He. Flatten: optical flow-guided attention for consistent text-to-video editing. arXiv preprint arXiv:2310.05922, 2023.
[7] Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Stan Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7623–7633, 2023.
[8] Yabo Zhang, Yuxiang Wei, Dongsheng Jiang, Xiaopeng Zhang, Wangmeng Zuo, and Qi Tian. Controlvideo: Training-free controllable text-to-video generation. arXiv preprint arXiv:2305.13077, 2023